Introduction
In DevOps, the Elite software delivery team refers to teams that can reliably release quality software faster with fewer failures and recovering much faster. These teams are great at continuous improvement: their CI pipelines run smoothly and efficiently. Measuring and improving CI performance is critical, because doing so has a direct impact on how fast, and how reliably, software can be delivered. If you don't track the key metrics, then it's tough to know if your pipelines are running as well as they could be.
With the help to reach this Elite Status in teams, we review specific North Star Metrics (DORA metrics for CI) like Success Rate, MTTR(Mean Time to Recovery), Duration, and Throughput, against sector benchmarks. These serve as guidelines to make sure the team is focused primarily on the most important aspects of optimization of the CI process.
In this article, we’ll explore what it takes to become an elite team and how tools like CICube can help you track and improve these key metrics. Plus, we’ll discuss how cultural factors, like team collaboration and platform engineering, play a crucial role in the success of high-performing teams.
Steps we'll cover:
- Defining Elite software delivery teams in DevOps ecosystem
- North Star Metrics and their benchmarks
- Using CICube for your GitHub Actions workflows to reach Elite Status
Defining Elite software delivery teams in DevOps ecosystem
How we define an elite team is based on a few key metrics known as North Star Metrics. These are the key indicators of how your CI pipeline is performing:
-
Success Rate: This will tell you how often your pipelines succeed-in other words, finish without failing. A high success rate means fewer bugs and higher ease of delivery.
-
MTTR (Mean Time to Recovery): This gives the time taken by your team to recover from a failed pipeline. The shorter this time is, the better your team is at fixing problems and moving forward.
-
Duration This essentially measures the lead time taken for a pipeline to execute through to completion. Elite teams do this within the shortest time possible, so as to get quicker feedback and more iterations.
-
Throughput: This is the number of successful pipeline runs that your team can complete in a given time period. The higher the throughput, the more work your team manages to push efficiently through the pipeline.
However, being an elite CI team doesn't quite revolve around just hitting those numbers; consistency, improvement over time, and how well these numbers stand against industry benchmarks like Elite Status and Median Performance count too.
Elite Status and Elite Benchmarks
Becoming an elite team will mean that you have met or exceeded a certain set of benchmarks for performance in the key metrics. Benchmarks put your team in perspective against industry standards.
Elite Benchmarks: The elite teams are consistently doing well in the four key North Star metrics we mentioned above. For example, an elite team will have a success rate of more than 90% on default branch, recover from failures(MTTR) in less than 60 minutes, keep pipeline duration less than 10 minutes, and finally ensure high throughputs-a synonym for running several workflows efficiently all through the day.
Median Performance: The median tells you how the average performing software team is performing. It acts like a benchmark for you to compare your improvement against to industry. You will know from where you need to improve by comparing your metrics with the median. For instance, if your MTTR is longer than the median, that is usually a signal that you need to concentrate on your recovery strategies.
These benchmarks enable teams to set clear goals for improvement-so they can progressively work toward elite performance-better releases of software faster, fewer disruptions, and a much more efficient continious integration.
Next, we'll explore these metrics and benchmarks.
North Star Metrics and their benchmarks
In CICube, we've developed CubeScore™️ system to help teams easily track and optimize their GitHub Actions CI pipelines using key metrics that define performance. These metrics are presented through clear charts and visualizations within the app, providing teams with a comprehensive view of their pipeline’s health.
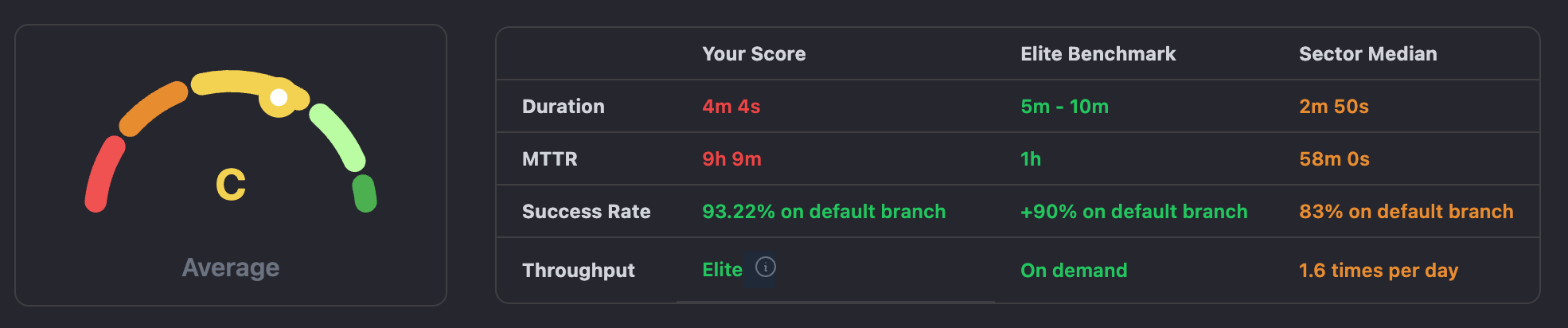
We'll use our live demo, featuring the React.js GitHub repository workflows, to show how CubeScore™️ works in real-time, offering actionable insights and helping teams achieve elite performance benchmarks.
Duration
Elite Benchmark: 5-10 Minutes
Median performance: 2.5 Minutes
First, we have Duration, which represents the average time taken by our CI. The importance of Duration comes because this directly contributes to how soon we get feedback on our code changes to iterate faster in product development.
The elite benchmark for Duration is between 5-10 minutes, with a median of about 3.3 minutes. At first glance, the lower duration actually seems to always be better. In reality, though, the elite teams usually have longer pipelines because of the more extensive testing, security scans, and other quality checks that may takes the time but produce higher-quality software and reduce problems in the future.
While it's tempting to keep the Duration as short as possible for the sake of speed, it's important to find a balance between speed and thoroughness. We want our pipelines to be fast, but also comprehensive enough to catch any issues early on.
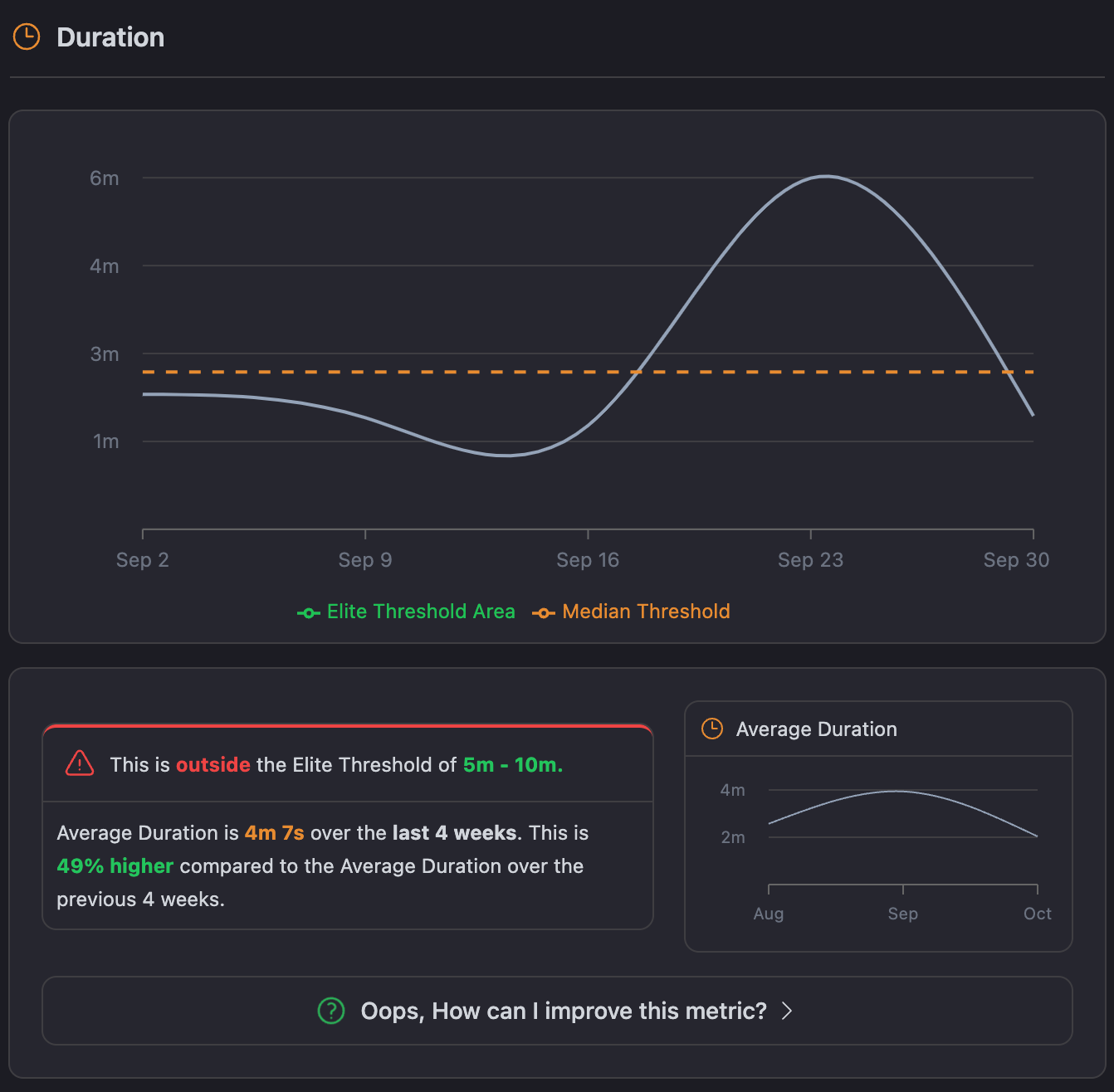
In CICube, the CubeScore™️ dashboard tracks the average duration of your pipelines over time. The chart compares your current duration against both the Elite Threshold (5-10 minutes) and Median Threshold, helping teams identify whether they are running efficiently or need adjustments.
For example, if your average duration is 4 minutes, you're within a good range but should still monitor for opportunities to streamline processes.
What is the ideal duration?
To get most value from your workflows: Try to get the duration as close to 10 minutes. This has been a generally accepted benchmark across the industry. It gives enough feedback on your code without slowing down your development.
You should focus on optimization earlier in the process by focusing most of your efforts on linting, unit tests, and static security tests. Save more comprehensive testing like dynamic security tests-DAST-performance tests, and end-to-end tests for the QA and Production branches. You can also use investments in scalable CI/CD practices, such as parallelization and caching, that will help speed up the pipeline without sacrificing quality.
Balancing speed and quality in CI pipelines
While developers are naturally inclined toward speed, platform engineers can significantly contribute to balancing that speed with quality. This role heavily influences the setting of guardrails to ensure pipelines include necessary tests without drawing out the duration for no good reason. It's finding that right balance: fast feedback, thorough enough to catch issues early, but not so fast as to skip over key checks of quality.
Thus, the team can get the best from both worlds by maintaining this balance: rapid development cycles of high-quality software able to cope with every functional and non-functional requirement.
Success Rate
Elite Benchmark: 90% or higher on the default branch
Median Performance: 83% on the default branch
The Success Rate is one of the most important North Star Metrics for measuring how well our CI is performing. It tells me the percentage of successful pipeline runs over a specific period and gives a clear picture of how stable the pipelines are and the overall quality of the code. The higher the success rate, the more reliable the pipelines are, which means smoother and more dependable releases.
The elite benchmark for success rate is 90% or higher on the default branch, while performance for the median tends to hover at around 83%. Reaching 90% isn't just about cutting down errors but about keeping the main branch stable and therefore trustworthy enough to deploy to production with confidence.
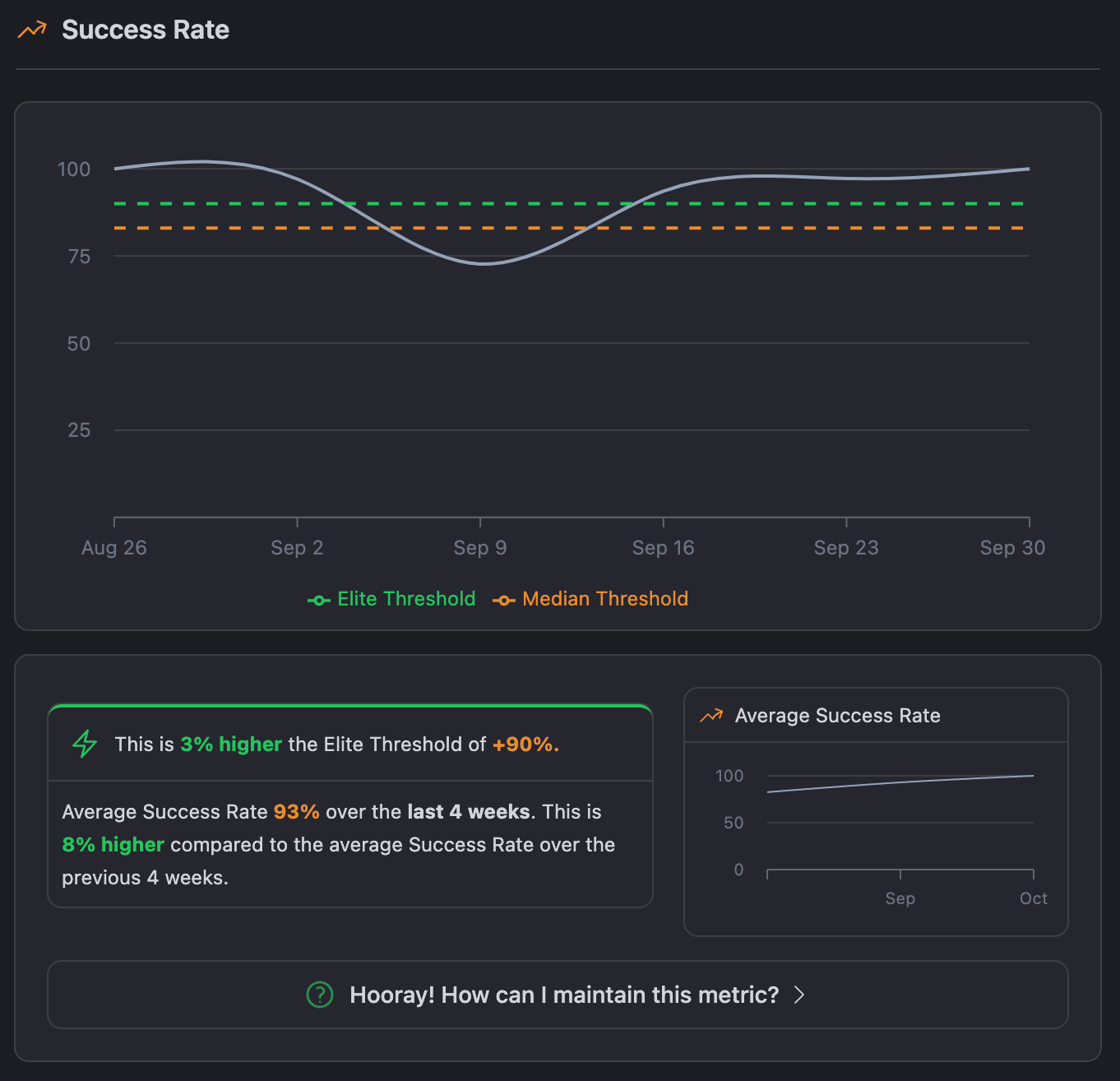
The Success Rate Chart in CICube's CubeScore™️ dashboard gives a clear snapshot of pipeline stability by showing the percentage of successful runs over time. In this example, the success rate averaged 93% over the last 4 weeks, surpassing the elite threshold of 90% and improving by 8% from the previous period.
This reflects fewer pipeline failures, contributing to a more stable codebase. The chart also allows teams to easily compare their success rates against the Elite and Median thresholds, helping to spot potential areas for improvement.
Why success rate matters?
A higher success rate reduces the amount of time spent troubleshooting and fixing broken pipelines. It also provides the development team with confidence in the code, which leads to faster, more frequent releases. However, a success rate alone does not prevent failures in pipelines from always being bad. Sometimes it just takes one failed workflow to provide just the right critical information to help catch bugs or security vulnerabilities earlier in a process.
For example, test-driven development or a fail-first approach may reduce temporarily your success rate, but will ultimately pay off in code quality. That's not about having fewer failures; it's about learning as fast and effectively as possible from the ones you have.
What is the ideal success rate for CI pipelines?
For the best pipeline stability, we should aim for a 90% success rate or higher on the default branch. This helps ensure that the mainline is always production-ready and doesn’t have major issues. While topic branches can have lower rates due to experimentation and feature development, it’s critical to keep the main branch stable.
By maintaining this, we can reduce downtime, release more frequently, and improve code quality by continuously pushing up our success rate.
Success rate isn’t everything: What else matters?
It’s easy to see a 100% success rate and think everything’s perfect with our CI pipelines. But, as we know, a high success rate doesn’t always give the full picture. A pipeline could pass all its tests but still be inefficient in delivering value quickly.
As someone responsible for keeping things on track, I’ve learned we need to look beyond the numbers. Success rates are important, but they should be paired with other key metrics, especially MTTR (Mean Time to Recovery). For example, if our team recovers quickly from failures, it tells me a lot more about the overall health of the pipeline than just seeing a good success rate alone.
Here are some practical ways to improve:
- Focus on recovery times: Smaller more frequent commits and smarter testing practices will bring quicker recovery times. This in turn will yield a higher success rate, lower failure rate over time.
- Set realistic baselines: Don’t just aim for perfection. Set clear success benchmarks for each branch or project and work towards steady improvement.
- Pay attention to patterns: Sometimes, the reasons behind a drop in success rate are not purely technical. Look for trends—do issues tend to spike on certain days, like Fridays or during busy release periods? These non-technical factors can affect your team’s performance just as much as code issues.
In the end, a team that can quickly recover from failures is often better positioned than one that rarely has failures but takes too long to fix things when they do go wrong.
Mean Time to Recovery (MTTR)
Elite Benchmark: 60 Minutes
Median Performance: 58 Minutes
This shows how fast we can recover when a pipeline fails. Issues in CI pipelines are unavoidable, whether it's due to a failed test or a build error. What really matters is how quickly we can pinpoint and fix those issues, minimizing downtime and keeping the code flowing smoothly.
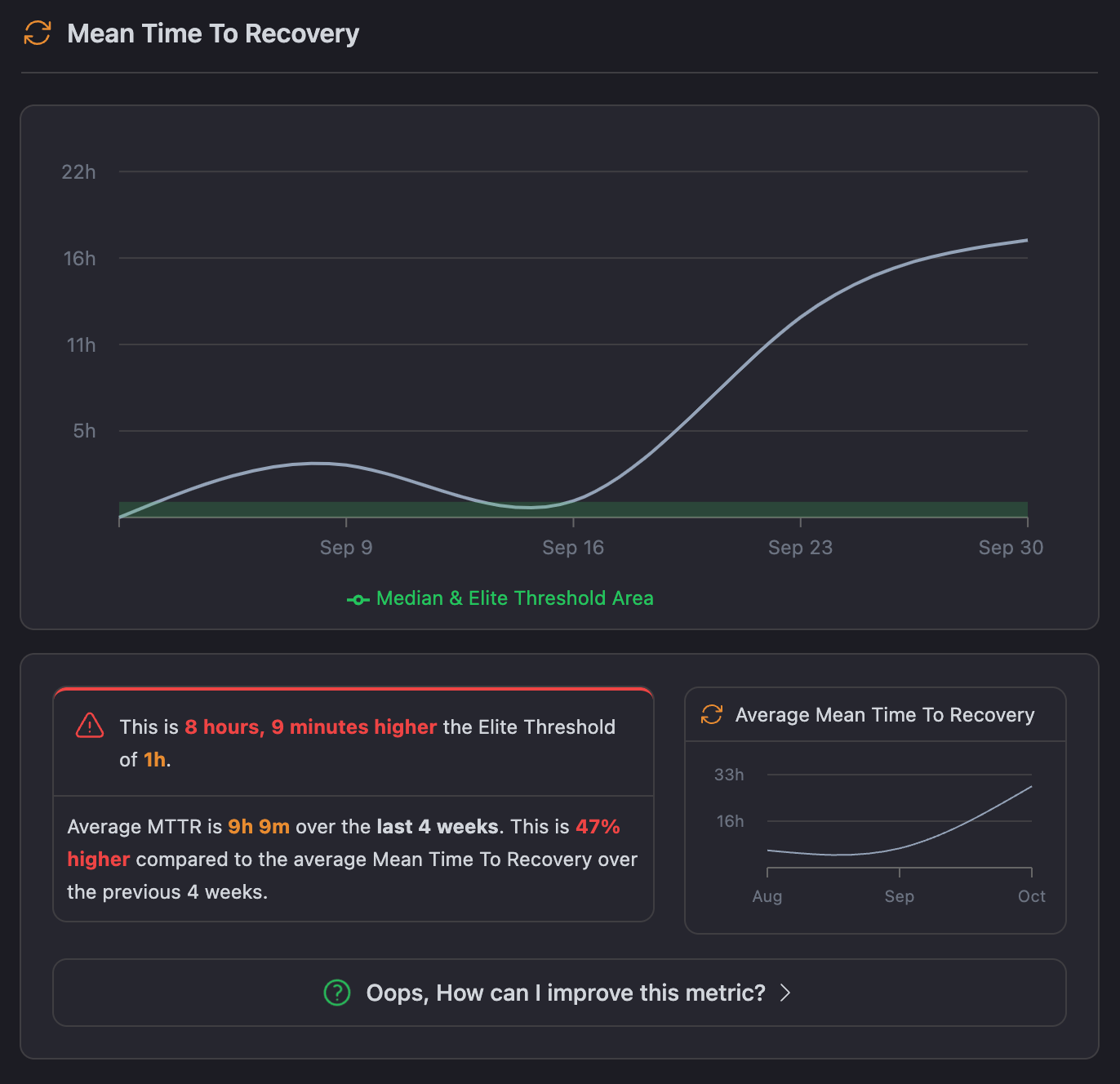
Looking at the CICube CubeScore™️ dashboard, we can see that our average MTTR has been 9 hours and 9 minutes over the past 4 weeks, which is quite a jump from the Elite Benchmark of 1 hour. This big gap shows we’ve got some work to do when it comes to resolving failures quickly. The graph also shows an upward trend, meaning it's taking us longer to recover from issues than in the previous period.
Why MTTR matters?
A lower MTTR means we can bounce back from failures faster, which keeps our pipelines moving with less disruption. This not only improves our overall throughput but also allows developers to spend more time building features rather than fixing broken builds. The faster our MTTR, the more efficiently we can handle issues and keep things running smoothly.
How to improve MTTR?
Here are some practical steps we can take to improve MTTR:
- Faster Feedback Loops: Keep pipeline durations short so we can detect and fix issues faster.
- Proactive Monitoring: Set up real-time alerts for failed builds so the team can jump on them immediately.
- Smaller Commits: Make smaller, more frequent commits, which makes it easier to track down where problems are occurring.
- Detailed Error Reporting: Ensure our error messages provide enough context to quickly locate and resolve issues.
Throughput
Elite Benchmark: Varies based on project needs
Median Performance: 1.68 times per Day
Throughput measures how many pipeline runs I can complete in a day. It’s an important way for me to see how efficiently we're pushing work through our CI pipeline. The more workflows we finish, the faster we can deliver value and iterate on our products.
For elite teams, throughput usually reflects a well-balanced and efficient process. They can handle a high volume of work without compromising on quality or stability. There's no one-size-fits-all benchmark for throughput, but my goal is to make sure it aligns with our business needs—whether that’s getting a lot of small updates out each day or running fewer, larger workflows.
For example, if we’re working on a mission-critical application, I’d aim to run workflows frequently to keep things stable and respond to changes quickly. On the other hand, if the project isn't as time-sensitive, I might focus more on thorough testing and quality, even if that means fewer runs.
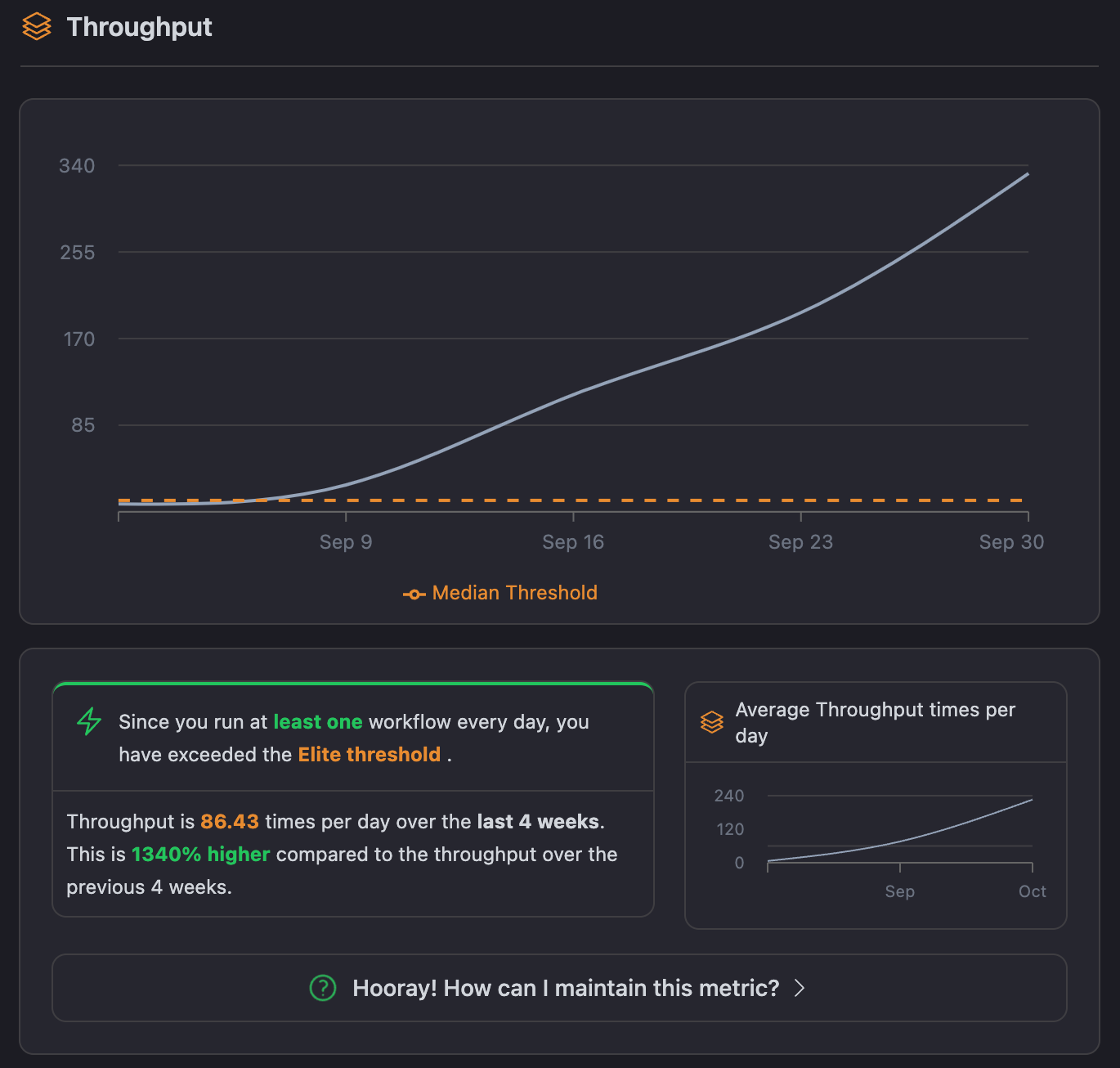
In the CubeScore™️ dashboard for CICube, we can track our throughput over time, comparing it to the median and elite benchmarks. In the chart example below, the median throughput is 1.68 workflows per day, meaning that teams are consistently pushing work through the CI pipeline. Elite teams, however, may achieve even higher throughput, especially if they automate more processes and streamline tasks.
What is the optimum Throughput?
There isn't a fixed target for throughput; what is ideal will depend upon the needs of your particular project and team. You do want to balance the throughput so that it maintains an ideal balance between productivity and quality.
This implies that high throughput isn't always a gauge for better performance, because usually teams may end up pushing poorly tested or low-quality work down in an attempt to achieve this high number of runs. This leads to even more problems further in the process. That's why both quality and volume in the pipeline become important to pay attention to.
Let's Recap What We've Covered
Sustained success
Elite software delivery teams enjoy one success after another, and this is just not a coincidence. They work towards creating stable pipelines that wouldn't break in every possible scenario. One secret behind their success: proper testing throughout each stage of the development cycle catches any issues before they ever hit production.
By following best practices such as test-driven development and continuous feedback loops, elite teams ensure their workflows pass more often than they fail. They also pay a lot of attention to Success Rate by monitoring it closely, addressing flaky tests, and keeping the default branch in a deploy-ready state.
Optimizing for performance
Speed is a factor that these teams essentially look at—it is quite frankly because the more time a build takes, there's a tendency to hold up the whole development process. This is exactly why an elite team would work on pipeline Duration in optimizing their workflow. Chunking into smaller steps, parallelizing whenever possible, is how they do this.
They also invest heavily in infrastructure and caching techniques to reduce the feedback loop. Automation also plays a huge role here: automating routine tasks such as linting, testing, and security checks accelerates delivery without cutting corners on quality.
Fast recovery
Even the best teams fail, but it is all about the speed of recovering. That's what made elite teams just elite. The elite teams put such a high premium on lowering MTTR so when something goes wrong, they can get to the bottom of it and fix it fast. They achieve this by maintaining clear monitoring and alerting systems that notify the right people whenever something fails.
Also, trunk-based development and small frequent commits help them to quickly narrow the range during which the problem occurred, reducing the impact of the error, therefore recovering in minutes rather than hours.
Maximizing throughput
While maintaining high speed and reliability, elite teams focus on Throughput, namely, how much work they push through the pipeline daily. But instead of simply pushing more work for the sake of it, elite teams know quality can't be sacrificed.
They maximize throughput, focusing on automation and efficiency to make sure every piece of work that goes through the pipeline adds value. They also continually refine their workflows, keeping away all unnecessary steps and rework. The end result? They are able to do more in less time, along with proficient code quality.
Equally, elite teams focus on four key drivers around the performance: success rate, speed, recovery, and throughput. This yields sustainable quality with higher delivery speed. They're not aiming merely at short-term gains; they're building systems to support long-term performance and continuous improvement.
Using CICube for your GitHub Actions workflows to reach Elite Status
Actionable insights
Just getting the right insights sets you on your way to being an elite team, and that's where CICube and its CubeScore™️ feature come in. CICube grants real-time visibility into your pipeline performance by tracking key CI metrics like Success Rate, MTTR, Duration, and Throughput. The CubeScore™️ dashboard clearly and visually compares your metrics against industry benchmarks, showing you exactly where to improve and what to prioritize for the most impact.
For example, if your MTTR trails behind the elite threshold, CubeScore™️ flags this and shows you how far away you are. In other words, you can take action sooner to fix the tests failing intermittently or to improve your recovery process. You won't have to guess because the data sets up your next steps.
Proactive monitoring
Elite teams do not wait for problems to surface; they avoid them. CICube's real-time monitoring and alerts keep you ahead of any issues. Whether it involves pipe failures, builds taking longer than expected, or fallen success rates, CICube will immediately have your team know about these.
It also sends tailored alerts based on what is most important to the team, such as when builds take too much time or a particular workflow always fails.
With proactive monitoring, you are not only reacting after problems have happened but are preventing them from turning into bigger disruptions in the first place. In such a way, you can focus on development and waste less time debugging.
Data-Driven decisions
Probably most important of all the benefits derived from working with CICube: it allows making data-driven decisions. Analytics on the platform let you benchmark yourself against elite in real-time. Whether this is Success Rate or Throughput, CubeScore™️ gives you the context to see how your team stacks up. This data-informed approach helps detect where your efforts lie in optimizing some pipeline or removing bottlenecks from the flow.
You may make better changes by data driving those decisions rather than gut feelings. Trends eventually begin to emerge over some time; these allow you to find some quick fixes and longer-term strategies towards sustaining elite performance.
Continuous optimization
The elite status is not reached once and for all; it's about continuous optimization. And that is where CICube helps: constant feedback. Every time a pipeline runs, CubeScore™️ will update with the latest data to show you how your changes are impacting the performance of this pipeline.
And through small improvements on a continuing basis, elite teams stay ahead or quickly adapt to challenges. For instance, if you feel that pipeline durations have begun to bleed, CubeScore™️ notifies you. You may fix those bottlenecks before they become bigger problems. It's this constant feedback-adjustment-feedback-adjustment cycle that keeps elite teams so good.
We Want Your Feedback!
At CICube, we’re always improving, just like the teams we support. If you’ve tried out our platform or used CubeScore™️ to optimize your pipelines, we’d love to hear from you! Your feedback is invaluable in helping us create the best possible experience for DevOps teams. Let us know what’s working well for you and where we can improve—we’re all about continuous improvement, and your input helps guide our journey toward that.
Feel free to share your thoughts, suggestions, or success stories with us!