Introduction
In the world of Kubernetes, overseeing the termination of pods is crucial for managing containerized applications effectively. Understanding why pods terminate is essential for ensuring stability and reliability.
In this blog post, we'll dive into the details of exit code 137 terminations, explore their underlying causes, discuss how to diagnose pods terminated with this code, and provide best practices for preventing such terminations in the future.
Steps we'll cover:
- What is Exit Code 137 in Kubernetes Pods?
- Why Exit Code 137 thrown in Kubernetes Pods?
- How to watch Pods Terminated with Exit Code 137?
- How to prevent from Unwanted Exit 137 Terminations?
- How to recovery from the error?
- Real World Case Studies
- How to Implement Efficient Memory Management Techniques?
What is Exit Code 137 in Kubernetes Pods?
Exit code 137 in Kubernetes pods might puzzle developers and system admins. It means that a container got a SIGKILL signal, usually because Kubernetes' Out Of Memory (OOM) killer had to stop it from using too much memory. This stops the container from using up all the memory, keeping the system stable.
Knowing how the OOM killer works helps understand exit code 137.
When a container uses more memory than allowed, the OOM killer jumps in to avoid system-wide issues. This stops the container so that other stuff on the node can keep running smoothly.
Why Exit Code 137 thrown in Kubernetes Pods?
Understanding why a pod gets exit code 137 is super important for folks using Kubernetes to keep their system reliable. Here are the big reasons to think about:
- Setting a tiny memory limit for the pod can make it go overboard and trigger the OOM killer.
- Memory leaks in an app, where extra memory isn't given back to the system, can slowly eat up the memory budget and lead to termination.
- Sometimes, unexpected jumps in app demand can also cause a 137 termination. These jumps might not be expected upfront and can happen when user traffic suddenly goes up or when there's extra data work during resource sharing.
- Messing up pod resources, where the memory limits don't match the real app needs, can lead to the OOM killer jumping in too often.
- Bad resource managing habits, like giving too much memory to lots of pods without keeping an eye on them, can stress out the node's resources. This not only risks setting off the OOM killer for single pods but can also hurt the overall performance and trustworthiness of the node or cluster.
How to watch Pods Terminated with Exit Code 137?
Recognizing these root causes is essential to implement more informed strategies.
The following command provides detailed information about the pod's current status, including the exit code among other details.
Simply run:
$ kubectl describe pod mypod
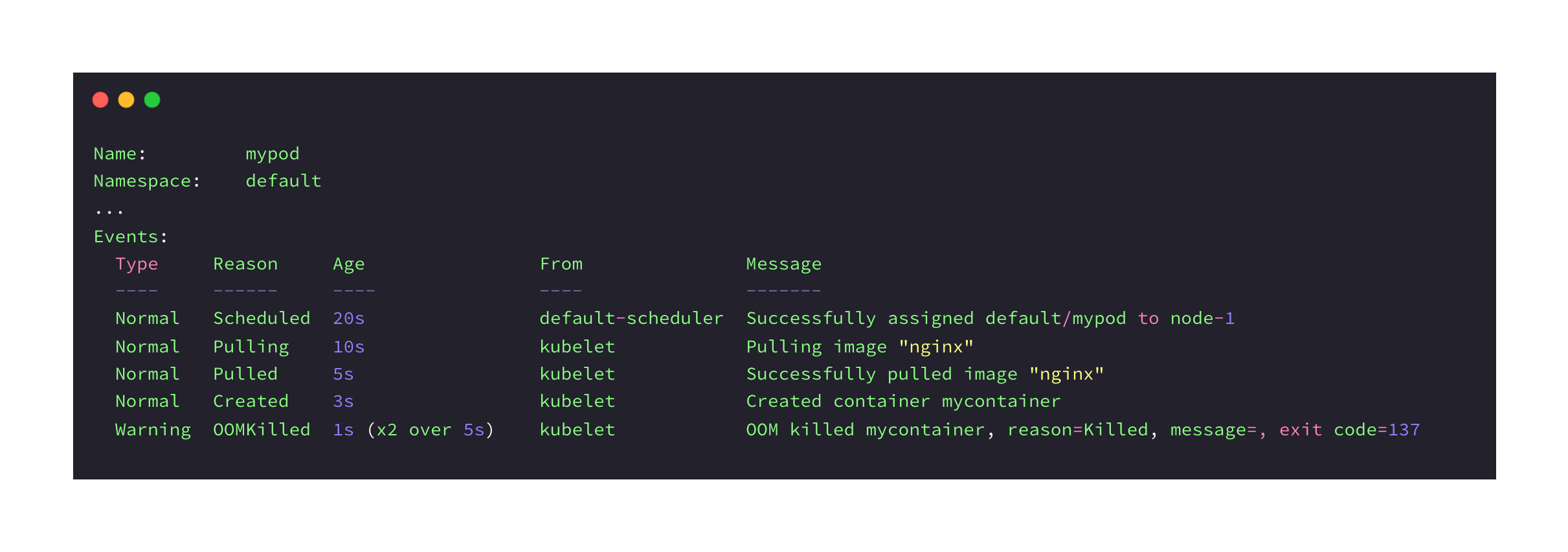
In this example, we're using the kubectl describe pod mypod command to fetch details about a Kubernetes pod. In the output, we see that the pod was successfully created and started, but later terminated due to an Out-of-Memory (OOM) condition in the container. A warning message indicates that the exit code was 137, which signifies that a SIGKILL signal was sent and the process was forcibly terminated.
By the way, you can use this command to get information about the overall status of pods.
kubectl get pods
Diagnosing pod terminations with exit code 137 needs a step-by-step approach to find out what's going on underneath. Here's how:
-
First, we can check out the pod's logs to see if there are any signs of memory issues or resource limits that might have caused the termination. Look for error messages or warnings that show things aren't working as they should.
-
Next, take a look at the Kubernetes events linked to the pod. These events show what actions Kubernetes took, like deciding to end a pod because it ran out of resources or the OOM killer stepped in.
-
Use commands like
kubectl describe pod <pod_name>andkubectl get eventsto get more info about what happened to the pod. -
Keep your eye on memory usage over time using Kubernetes metrics and tools like Prometheus with Grafana. Look for any trends or big changes that could lead to a termination. Set up alerts to let your team know if there's a problem before it gets worse.
-
If you can't find the problem right away, try profiling the app for memory leaks or bad memory use. Use tools that match the app's programming language to find out if it's holding onto memory it doesn't need or using too much. Then, use what you find to make things better.
How to prevent from Unwanted Exit 137 Terminations?
Crafting a smart plan to avoid unexpected pod terminations with exit code 137 starts with setting up resources thoughtfully.
Let's break it down:
- You can set memory limits that match what the app really needs by checking how it performs under different amounts of work.
- Keep an eye on how resources are used and look for any changes that could be a problem.
- Use tools that show you how memory is used to help decide if you need to change how much memory your app gets.
- Make sure your app uses memory efficiently by writing good code and fixing any memory leaks.
- We can use special tools to find any hidden problems that could cause exit code 137 terminations.
- Make alerts that go off if your app uses too much memory, so you can fix the problem before it gets bad.
- When an alert goes off, act fast by changing how much memory your app gets or looking into why it's using so much.
How to recovery from the error?
Recovery Strategy Using Kubernetes Features
When it comes to recovering from unexpected pod terminations, we can start by using features built into Kubernetes. Things like liveness and readiness probes keep an eye on how containers are doing. If a container has memory problems or other issues, these probes can restart it right away. This quick response can often keep things running smoothly until you find a permanent fix.
Managing Application Demand with Horizontal Pod Autoscaler (HPA)
Another helpful tool in Kubernetes is the horizontal pod autoscaler (HPA). It helps us to manage sudden increases in demand for your application, which can sometimes lead to using too much memory. The HPA adjusts the number of pod copies based on how busy your app is, so it doesn't use more memory than it should.
Implementing Comprehensive Alerting Mechanisms
To stay on top of any issues that come up, it's important for us to have good alert systems in place. We recommend ools like Prometheus can send you alerts when memory use gets too high. This lets you jump in quickly to figure out what's going on and fix the problem before it gets worse.
Real World Case Studies
Now, let's look at a real-life example of dealing with the issues we've talked about.
Evaluating the Problem
For example, let's say there's an online store called E-Shop. During busy shopping times, they noticed their app was having a lot of problems. It turns out, pods were shutting down with exit code 137 because they didn't have enough memory to handle all the people using the app.
Multi-Faceted Approach
To fix the problem, E-Shop's tech team did a bunch of things. They looked at how the app was using memory and found ways to use less. Then, they changed how much memory each part of the app could use to handle busy times better. They also set up alerts so they'd know if the app was using too much memory.
Positive Outcome
All these changes meant there were way fewer exit code 137 errors. That meant people using the app had a better experience, especially during big sales.
How to Implement Efficient Memory Management Techniques?
In this bonus section, we'll talk about some simple ways to make sure your app doesn't use too much memory.
-
Optimize Code: We should look at your app's code and see if there are ways to use less memory. Use smaller data structures and make sure you're not using more memory than you need to.
-
Release Resources: When our app is done using something, make sure it gives it back. Close files, release database connections, and free up memory when you're done with it.
-
Detect Memory Leaks: We can use tools to find memory leaks in your code. Profile your app's memory usage to see where you're using too much.
-
Utilize Profiling Tools: Use tools that are made for your programming language to see how your app uses memory. They'll help you find and fix memory problems.
-
Test and Monitor: Make sure to test your app and see how it uses memory in different situations. Keep an eye on memory use when your app is running to catch any issues early.
By doing these things, you can make sure your app uses memory efficiently.
Conclusion
In the end, knowing about Kubernetes pod termination and exit code 137 is really important for keeping your apps running smoothly. By following best practices, keeping an eye on things, and fixing problems quickly, you can make sure your Kubernetes apps stay reliable and stable.