This article was updated on December 25, 2024, to include advanced debugging tips, real-world examples, and best practices for managing Kubernetes Jobs, based on my latest experiences with production-grade clusters.
Introduction
TL;DR: What are Kubernetes Jobs?
Kubernetes Jobs represents a powerful type of resource that may enable one-shot or batch job workloads in running into the Kubernetes cluster. It executes a prescribed number of parallel Executions for performing tasks and performs retries along with handling associated logic at failure; all of it can manage several workloads like database migrations, data processing, and maintenance on schedules.
After 8+ years of working with Kubernetes in production environments, I have found Jobs to be one of the most reliable ways to handle one-off tasks. Be it database migrations, data processing in batches, or routine maintenance on a schedule, I will show you exactly how I use Jobs to ensure task completion, handle failures gracefully, and maintain a clean cluster.
In this tutorial, I will be sharing:
- My journey from basic Jobs to complex workflows
- Common pitfalls that I have fallen into, and how I got out of them Production-tested configurations I use every day Introduction:
- Tips for debugging when things go wrong
- Effectively automates batch processing.
- Ensures that the job will be completed with retry mechanisms.
- Simplifies scheduling through CronJobs.
- Handles failures gracefully with backoff limits.
- Optimizes resource usage, limiting CPU and memory.
Steps we will cover:
- Introduction
- Why I Love Kubernetes Jobs
- My Most Common Use Cases for Jobs
- Scheduled Tasks Done Right
- Interactive Job Creator
- Lessons Learned the Hard Way
- Step-by-Step Guide: Running a Kubernetes Job
- Debugging Tips from Everyday Use
- Kubernetes Jobs vs. Alternatives
- Conclusion
Why I Love Kubernetes Jobs
When I first started working on Kubernetes in 2016, doing batch tasks with regular pods was attempted. It was a nightmare-driving. Tasks would silently fail/pods would hang and were taking hours to debug that. Then, jobs discoveries were made, and 'voilà.' A world of difference: having to deal with simple workloads was no longer all-consuming.
The diagram below shows how Kubernetes Jobs manage tasks, retries, and completion:
My Most Common Use Cases for Jobs
Over the years, I have used Jobs for various purposes, including:
Database Migrations Last year, I had to plan a major database schema update among 20 microservices. Instead of doing the updates manually, I created a Job:
- Database connectivity verified
- Applied migrations in the right order
- Logged each step for auditing
- Notified our team on completion
Here is the actual Job configuration I used:
apiVersion: batch/v1
kind: Job
metadata:
name: schema-migration-v2
labels:
app: user-service
type: migration
spec:
backoffLimit: 3
template:
spec:
containers:
- name: migrator
image: our-registry/db-migrator:v2.3
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: db-config
key: host
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-creds
key: password
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "200m"
restartPolicy: Never
Data Processing at Scale One of my clients needed to process millions of customer records daily. I set up a parallel Job:
- Split the data into chunks
- Processed them simultaneously
- Gracefully handled failures
- Maintained processing order
The key was setting the right parallelism and completion parameters:
apiVersion: batch/v1
kind: Job
metadata:
name: customer-data-processor
annotations:
description: "Processes daily customer data updates"
spec:
parallelism: 5 # Found this sweet spot after testing
completions: 20 # Each completion handles ~50k records
template:
spec:
containers:
- name: processor
image: our-registry/data-processor:v3
volumeMounts:
- name: data
mountPath: /data
env:
- name: BATCH_SIZE
value: "50000"
- name: PROCESSING_THREADS
value: "4"
volumes:
- name: data
persistentVolumeClaim:
claimName: batch-data
Scheduled Tasks Done Right
After an eternity of cron headaches, I've settled on this pattern for scheduled Jobs:
apiVersion: batch/v1
kind: CronJob
metadata:
name: nightly-cleanup
spec:
schedule: "0 2 * * *" # Runs at 2 AM
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
containers:
- name: cleanup
image: our-registry/cleanup:v1
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "200m"
restartPolicy: OnFailure
This CronJob can be used in a Kubernetes cluster for:
- Running periodic cleanup jobs at 2 AM, such as purging temporary files.
- Keeping the cluster tidy by limiting the amount of logs for jobs completed or failed.
- Managing resource usage efficiently to maintain the stability of the cluster.
Interactive Job Creator
I have built this interactive tool in order to assist you in constructing Jobs properly. It is based on the following patterns that have proved themselves in my production environments:
Generated YAML
Lessons Learned the Hard Way
Resource Management
In my early days, I didn't set resource limits. Big mistake. One runaway Job consumed all cluster resources. Now I always configure:
- Reasonable CPU/memory limits
- Appropriate requests based on actual usage
- Resource spike alert monitoring
Error Handling
I once had a Job that kept failing silently. The fix? Proper backoff limits and restart policies:
spec:
backoffLimit: 3 # Don't retry forever
activeDeadlineSeconds: 600 # Time limit for the entire Job
template:
spec:
containers:
...
restartPolicy: OnFailure # Better than Never for most cases
Cleanup Strategies
Left unchecked, completed Jobs can clutter your cluster. My cleanup strategy:
- Set TTL after completion
- Use labels to filter easily
- Implement automated cleanup jobs
Step-by-Step Guide: Running a Kubernetes Job
Let’s walk through creating and managing a Kubernetes Job using realistic examples from a cicube use case. Here’s how you can create, monitor, and debug a Job step-by-step.
Create a Job
First, create a YAML file (data-processor-job.yaml) with your Job configuration. Here’s an example:
apiVersion: batch/v1
kind: Job
metadata:
name: cicube-data-processor
spec:
template:
spec:
containers:
- name: data-processor
image: cicube/data-processor:v1.0
command: ["python", "process.py"]
args: ["--batch-size=1000"]
restartPolicy: Never
backoffLimit: 3
Apply the Job using kubectl:
kubectl apply -f data-processor-job.yaml
Output:
job.batch/cicube-data-processor created
Check Kubernetes Job Status
After creating the Job, you can check its status:
kubectl get jobs
Output:
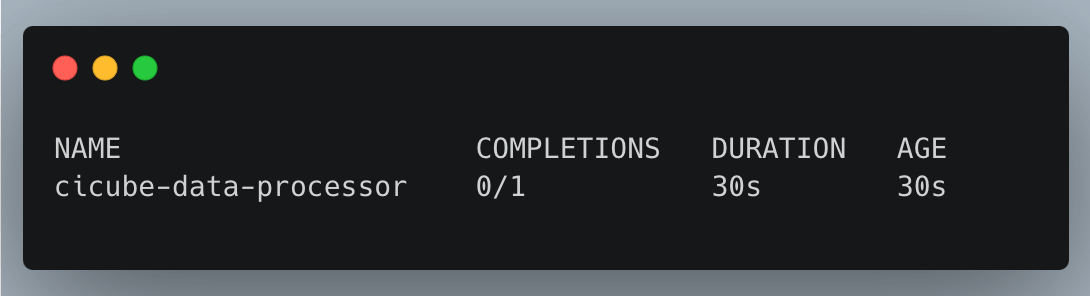
Inspect Job Details
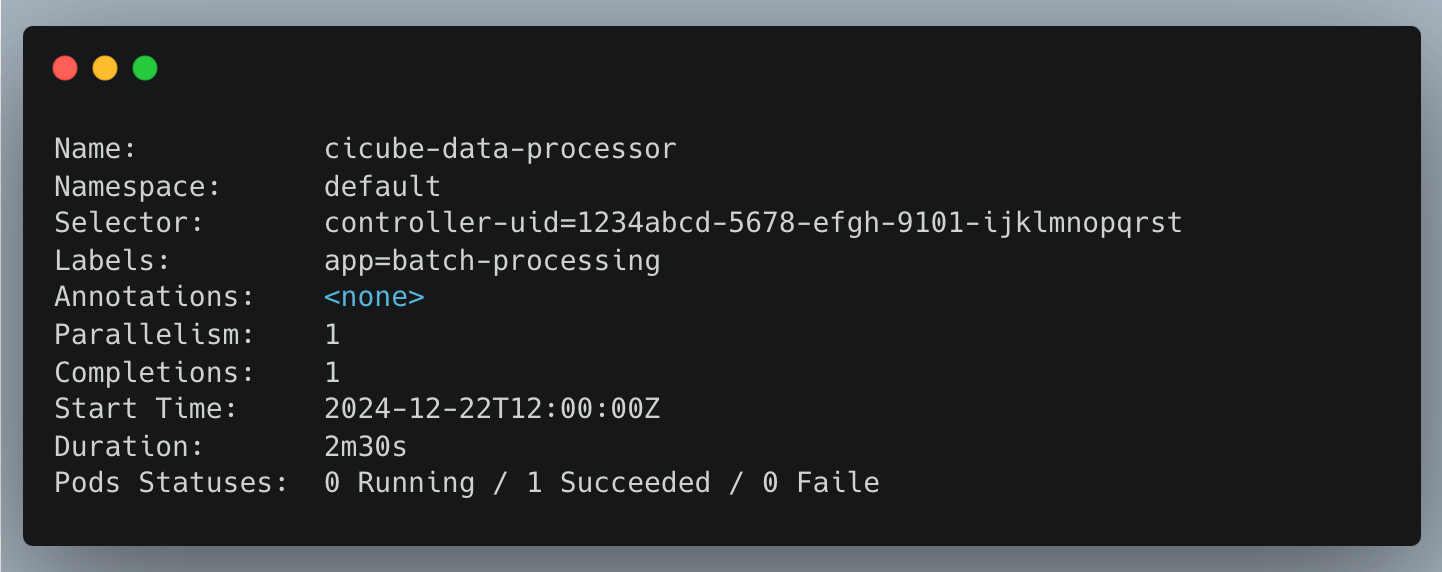
To see more details about the Job:
kubectl describe job cicube-data-processor
Output:
Check Pods Created by the Job
To list the Pods managed by this Job:
kubectl get pods --selector=job-name=cicube-data-processor
Output:

View Logs
To debug or verify the Job’s output, check the logs of the Pod:
kubectl logs cicube-data-processor-xyz123
Output:
Processing batch of 1000 records...
Batch processing complete. Exiting.
Clean Up the Job
After the Job has completed, you can delete it to free up cluster resources:
kubectl delete job cicube-data-processor
Output:
job.batch "cicube-data-processor" deleted
Debugging Tips from Everyday Use
When things go wrong, and they will, here's my debugging checklist:
- Firstly, confirm the status of the job:
kubectl get jobs -o wide
- Now, go into the pods:
kubectl get pods --selector=job-name=<job-name>
- Check the logs-this has saved me a lot of times:
kubectl logs job/<job-name>
- Job Description - More details:
kubectl describe job <job-name>
Kubernetes Jobs vs. Alternatives
Here's a comparison of Kubernetes Jobs with regular Pods and Deployments to highlight their differences:
| Feature | Kubernetes Jobs | Regular Pods | Deployments |
|---|---|---|---|
| Handles retries on failure | ✅ | ❌ | ❌ |
| Scheduled tasks | ✅ (with CronJobs) | ❌ | ❌ |
| One-time execution | ✅ | ❌ | ❌ |
| Resource management options | ✅ | ✅ | ✅ |
| Best for batch processing | ✅ | ❌ | ❌ |
Conclusion
Having used Kubernetes Jobs in production for years, I can attest that they are one of the most reliable ways to perform batch processing and scheduled tasks. Start with simple examples, understand the basics, and then implement more complex patterns when the need arises.
Have questions about running Jobs in your environment? Always happy to help, fellow Kubernetes enthusiasts - feel free to reach out!