Introduction
I've been looking into ways to improve our ability to analyze data, and I found something really interesting that I believe could help us all a lot. So, what's the big deal with AWS Redshift?
It's essentially a fully managed data warehousing service that simplifies the whole process of running and scaling analytics. What caught my eye is how it doesn't require us to get into the nitty-gritty of managing a data warehouse infrastructure. This means we can focus more on analyzing our data rather than worrying about the backend stuff.
Redshift allows for real-time and predictive analytics on a wide range of data sources. This includes everything from operational databases and data lakes to third-party datasets. Imagine being able to gain insights from our entire data ecosystem without the usual headaches!
Steps to be covered:
- Introduction
- What is AWS Redshift?
- Why Use AWS Redshift?
- Real-World Projects Using AWS Redshift
- What are advantages of using AWS Redshift?
- Comparison: Amazon Redshift vs Amazon RDS (PostgreSQL, MySQL)
- AWS Redshift Pricing: On-Demand vs Serverless?
- AWS Redshift SDK Resources
- Conclusion
What is AWS Redshift?
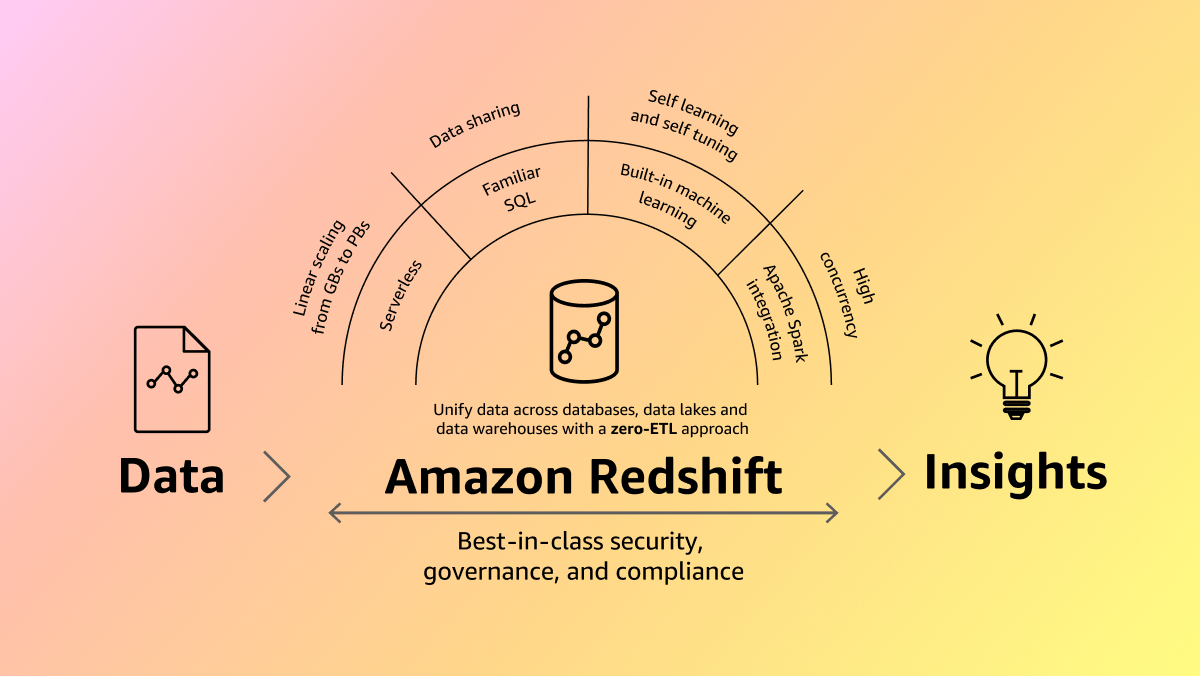
AWS Redshift is a powerhouse when it comes to data warehousing services. It's designed to handle massive volumes of data, talking in the range of exabytes, which is quite mind-blowing if you ask me. What's even better is its ability to process both structured and unstructured data, making it quite versatile for various data analysis tasks we might have.
Setting up Redshift is a breeze, which is something you'd appreciate. It fits right into the AWS ecosystem, allowing us to get it up and running with just a few clicks. Plus, it supports a wide range of data import methods, giving us the flexibility we need to bring in data from different sources.
Security is top-notch with Redshift. It ensures our data is always encrypted, offering that peace of mind we need when dealing with sensitive information. And when it comes to extracting insights from our data, AWS Redshift promises a user-friendly interface that makes it easy to set up clusters without getting bogged down by infrastructure management.
It becomes clears that Redshift could be a game-changer for everyone, especially with our growing needs for efficient data handling and analysis.
Why Use AWS Redshift?
Picking AWS Redshift for storing your data offers many advantages. Here's why you might consider it:
First off, the scalability is pretty amazing. We can start with just a little data and scale up to a massive amount without any interruptions. It means we won't have to worry about outgrowing our setup or facing downtime as we expand.
Performance-wise, Redshift uses something called columnar storage, which basically means it's super efficient at handling our queries, even as our data gets bigger. This is great for pulling insights quickly, which, as you know, is crucial for us to stay ahead of the curve.
On the security front, Redshift has us covered too. Everything's encrypted, whether it's just sitting there or if we're moving data around. Plus, with all of AWS's security features, we can make sure we're meeting all those compliance requirements we talked about last week.
And the cost? It seems pretty reasonable. We only pay for what we use, and there's flexibility in choosing the pricing model that best fits our budget. Looks like it could be a good way to keep costs in check while still getting a powerful tool for our data needs.
Real-World Projects Using AWS Redshift
It really opened my eyes to the practical applications of Redshift beyond the usual marketing jargon, and I felt compelled to share these insights with you.
| Industry | Project Use Case | Outcome |
|---|---|---|
| E-commerce | Analyzing customer behavior and sales data | Enabled personalized marketing and optimized product placement |
| Healthcare | Aggregating patient records for better healthcare outcomes | Improved patient care and operational efficiency |
| Financial Services | Analyzing market data for investment insights | Informed investment decisions and risk assessment |
| Smart Cities | IoT data analysis for urban management | Optimized traffic, improved public transport, and emergency response |
These examples really highlight how Redshift's data analysis capabilities are being put to good use across a variety of sectors. It's not just about the technology; it's about the outcomes and improvements these projects bring to businesses, cities, and everyday life.
What are advantages of using AWS Redshift?
Firstly, AWS Redshift offers a cost-effective solution compared to alternatives like Teradata or Oracle. It's approximately 5% of their prices.
In terms of technical advantages, Redshift's speed is unmatched due to its utilization of MPP technology. This enables us to process large datasets rapidly, which is crucial for our analytical needs. Additionally, the comprehensive data encryption ensures the security of our sensitive information.
I appreciate Redshift's compatibility with familiar tools, as it is built on PostgreSQL. This allows us to use our preferred SQL, ETL, and BI tools without being restricted to Amazon's ecosystem.
Another significant advantage is Redshift's intelligent optimization capabilities. It provides tools and suggestions for query improvement and database optimization, streamlining our processes and saving time.
Lastly, Redshift's scalability is noteworthy. It automatically scales to accommodate increasing workloads, ensuring consistent performance without requiring manual intervention.
Overall, AWS Redshift presents a compelling solution for our data warehousing requirements, offering affordability, speed, security, compatibility, optimization, and scalability.
Comparison: Amazon Redshift vs Amazon RDS (PostgreSQL, MySQL)
When it comes to storing and managing data on AWS, Amazon Redshift and Amazon RDS (Relational Database Service) are two robust services, each with unique strengths. Here's a simple comparison to help you understand their differences and determine which service might better suit your needs.
| Feature | Amazon Redshift | Amazon RDS |
|---|---|---|
| Primary Use Case | Designed for data warehousing and analytics on large datasets. | Ideal for traditional relational database management for applications. |
| Database Model | Optimized for columnar storage, facilitating fast retrieval of large data sets. | Utilizes row-oriented storage typical of relational databases like PostgreSQL and MySQL. |
| Data Analysis | Suited for complex queries across large datasets, supporting data lakes. | Best for transactional databases with simpler queries. |
| Performance | Delivers high performance on analytical workloads with massive datasets. | Optimized for transactional workloads with efficient CRUD operations. |
| Scaling | Allows separate scaling of storage and compute for increased flexibility. | Scales compute and storage together, simplifying management but with potential limitations. |
| Pricing | Tailored pricing for data warehousing workloads, potentially higher for large datasets. | Generally cost-effective for smaller to medium-sized databases. |
| Maintenance | Managed service but may require tuning for optimal performance. | Fully managed, including automated backups, patching, and maintenance. |
| Security | Offers robust security features, including encryption and IAM policies. | Provides similar security features but tailored for database management. |
| Use Cases | Well-suited for data warehousing, big data analytics, and large-scale data processing. | Ideal for web applications, mobile apps, and legacy application hosting. |
In summary, both Amazon Redshift and Amazon RDS provide valuable solutions tailored to specific needs. Understanding your data requirements and operational goals is essential for choosing the service that best fits your organization's needs.
AWS Redshift Pricing: On-Demand vs Serverless?
AWS Redshift has turned out to be a game-changer in terms of cost-efficiency. Believe it or not, it's about 1/20th the cost compared to traditional giants like Teradata and Oracle. This significant saving could be a massive advantage for extensive data warehousing and analytics needs.
What's more, AWS Redshift offers two flexible pricing models that cater to various requirements - On-Demand and Serverless.
The On-Demand option seems ideal for our kind of setup where workloads can be unpredictable. It offers the flexibility of paying as we go for compute capacity, which means we're not tied down by long-term commitments or upfront investments.
Then there's the Serverless option, which I find particularly exciting. It's perfect for those instances where we want hassle-free data analysis without the burden of managing infrastructure. We'd only pay for the data processed, making it an economical and efficient choice for ad-hoc analysis or projects with variable data processing needs.
It seems to offer the right blend of cost-efficiency, flexibility, and scalability we've been looking for in a data warehousing solution.
On-Demand Pricing
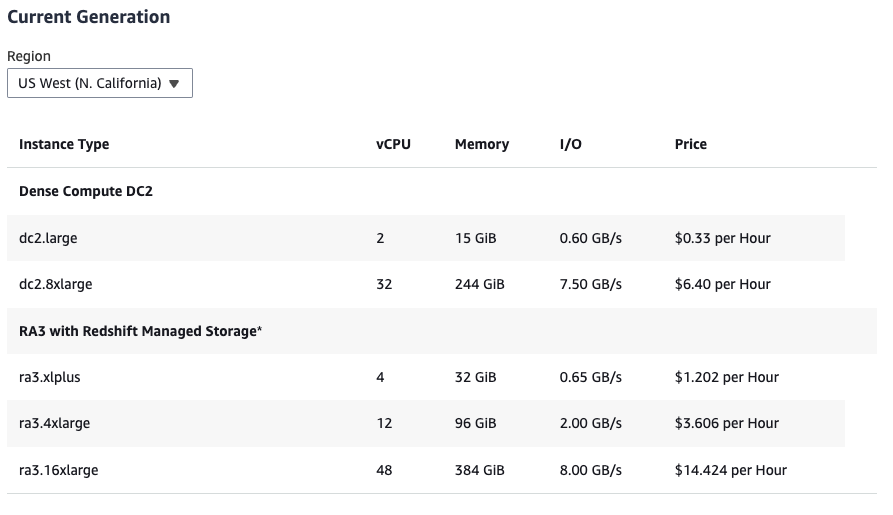
The On-Demand pricing model allows you to pay for the compute capacity by the hour with no long-term commitments or upfront payments. This model is ideal for users who prefer a pay-as-you-go approach, offering the flexibility to start and stop at any time based on your needs. Prices vary based on the type and number of nodes in your cluster.
Serverless Pricing
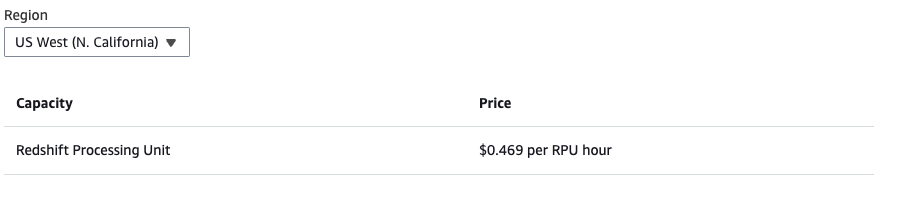
The Serverless option is designed for users who require data warehousing capabilities without the need to manage a cluster. With Serverless, you pay only for the amount of data processed by your queries, eliminating the need to provision or manage any infrastructure. This model simplifies the data analysis process, especially for occasional querying or varying workloads.
AWS Redshift SDK Resources
AWS Redshift is supported through AWS's comprehensive SDKs available for multiple programming languages. Here are some of the key SDKs with links to their documentation and resources:
| SDK Language | Documentation Link | Description |
|---|---|---|
| Java | SDK Documentation | Direct integration for managing Redshift instances |
| .NET | SDK Documentation | Facilitates .NET applications with Redshift |
| Python (Boto3) | SDK Documentation | Python SDK for AWS, including Redshift |
| JavaScript (Node.js) | SDK Documentation | Enables Node.js apps to interact with Redshift |
| AWS CLI | CLI Documentation | Command Line Interface for AWS services |
Conclusion
I've been wrapping my head around various data warehousing solutions lately, and I must say, AWS Redshift has caught my attention in a big way
Redshift is not only affordable but also offers great performance and flexibility. It's impressive how it makes data storage and advanced analytics available to businesses big and small. Its cost efficiency is pretty good when you compare it to traditional heavyweights like Teradata and Oracle. We're talking about a potential cost reduction to a fraction of what we might have considered normal.
One of the things that I appreciate the most is how Redshift integrates seamlessly with tools we're already familiar with. This, coupled with its rock-solid security features, positions it as a compelling choice in the crowded market of data solutions.
Usage models deserve a mention too. With On-Demand and Serverless options, Redshift ensures that we can align our project requirements and budgets effectively, essentially paying only for what we use. This flexibility can be a game-changer for managing costs without compromising on the power or scale of THE data analytics.